Constant-time code verification with Memory Sanitizer
In the cryptography context, the side-channel attacks are about exploiting computer system implementation to gain information about the secret key. First such attacks were introduced by Paul Kocher in his paper called “Timing Attacks on Implementations of Diffie-Hellman, RSA, DSS, and Other Systems”. Since then attacks were much improved to include different sources of side-channel information like power consumption, and electromagnetic and acoustic emissions. Since then attacks were much improved to include different sources of side-channel information like power consumption, and electromagnetic and acoustic emissions. Since then, those attacks were proved multiple times to be practical.
Timing attacks are a subset of side-channels in which information about the execution time of a cryptographic primitive is exploited to break the system. One of the most appealing advantages over other side-channel attacks is that those attacks can be applied remotely, through the network. For an attack to be useful, the execution of the cryptographic primitive must depend on secret material. In brief, constant-time implementation is crafted in a way that execution doesn’t depend on secret data. Article by Thomas Pornin, author of BearSSL, explains in detail what it means here.
In many cases, checking if the implementation is constant-time is not trivial and tools are needed. Adam Langley’s developed a tool called ctgrind. The idea is to extend and use a tool detecting Use of Uninitialized Memory (UUM). The tool is called Memcheck, which runs in the Valgrind framework.
Memory Sanitizer (MSan) is another UUM detector. It is a part of the LLVM project, which integrates with the clang compiler. This blog post briefly describes how it works and how to use it for checking the constant-time implementation in a “a toy” code. Finally, after introducing useful helper it shows a result of integrating it with existing cryptographic implementations and compares it to Memcheck.
How does the UUM detector work?
Techniques used for detecting Use of Uninitialized Memory, implemented in tools like Valgrind’s Memcheck or LLVM’s Memory Sanitizers, has been developed over the years and currently are quite advanced. At high level both Memcheck and MSan are similiar.
The main difference between Memcheck and Memory Sanitizer is that in the case of Valgrind binary instrumentation is done at startup. Memcheck uses the Valgrind framework for instrumenting already compiled binary. In contrast, Memory Sanitizer instruments code at the compilation stage and leverages mechanisms implemented in LLVM, like its intermediate representation. Memcheck combines the detection of UUM and memory addressability bugs in a single tool. In the case of LLVM, these are implemented in two different tools - Memory Sanitizer (MSan) for detecting UUMs and a sibling tool called AddressSanitizer (ASan) for addressability bugs. There are down and upsides to both approaches. The approach taken by MSan allows for execution to be magnitude faster and have almost no startup penalty.
Except for those differences, at a high level, the internals of both Memcheck and MSan are similar. UUM detector tracks the state of every bit of memory or register used by the program. It uses a concept called shadow memory (Valgrind calls shadow memory a VBITS’s), which stores information on whether each bit of memory was properly initialized.
It allows using uninitialized memory if it is “safe” to do so. For example, copying it from one place to the other is not a problem. It reports a problem only when the execution of a program depends on an uninitialized state. For example, when branching, dereferencing a pointer or using uninitialized memory as for array indexing. That’s exactly what we need to test constant-time functions. Uninitialized memory can be propagated to other variables in the code (i.e. copying). To track the propagation, UUMs implement propagation of the shadow memory - when the uninitialized value is used as an operand of a “safe” operation, its state is propagated to the result of that operation. The new shadow value is computed based on the values of the operands and their shadow values.
Let’s summarize those concepts by analysing a concrete example. Function on the left side adds 1 to an argument n and returns the result. On the right side, we see the state of the shadow memory and the current values of variables. Uninitialized memory is marked red and initialized is blue. In this example, the function is called with argument n=6. The 12 least significant bits of an argument n are uninitialized.

The function creates on a stack temporary variable b and assigns 1 to it. Variable is properly initialized, hence its shadow memory is marked blue. The second variable r is initially uninitialized. In addition, the UUM detector looks at shadow bits of both operands and calculates a new shadow value for variable r. Adding uninitialized to initialized results in uninitialized. So, the shadow memory for r is the same as for the argument n (4 most significant bits have initialized the rest is not). In addition, the operation doesn’t change program flow it doesn’t trigger the UUM.
It should also be noticed that resulting shadow memory depends, on the operation being done as well as the state of shadow memory of both operands.
Origin tracking helps to understand potential problems. It assigns an ID to each variable and serves as an identifier that created uninitialized bits in shadow memory. Once UUM is triggered, the detector uses those IDs to backtrack the origin of uninitialized values and print them in the final report. MSan implements more advanced origin tracking, its report shows lines of code where uninitialized memory was created as well as places at which it was propagated before UUM was triggered (see the result of running “toy example” above). In the case of MemorySanitizer, it is enabled by providing -fsanitize-memory-track-origins= flag to the compiler, in case of Valgrind it is --track-origins=yes option.
Toy example
A constant-time table lookup is an important tool in secure, cryptographic implementations. For instance, it is used for the implementation of elliptic curves-based schemes, like ECDH - widely deployed on the Internet and used by HTTPS connection key exchange schemes. In that system, the (rational) point on the elliptic curve is multiplied by a scalar. A scalar is used as a secret key and hence it must be protected against leaks. The optimized version of such multiplication may use, so-called window technique. In this case, to speed up computation, an algorithm starts with pre-computing small multiplies of a point (like \([0]P, [1]P, \cdots, [15]P\), for fixed window size \(\textit{w}=4\)) and stores them in some table. Then, scalar-by-point multiplication consists of slicing the binary representation of a scalar into equal \(w\)-bit long pieces, iterate over such split and use those pieces for point multiplication (see here for a detailed description of a technique). Most importantly at each iteration, an algorithm gets a small multiply of a point \([k]P\) for \(k<15\) from the table. That is a time variable operation - as the value may be loaded from different locations (CPU register, cache or RAM). An attacker can then try to guess secret scalar by exploiting those time differences. Hence, lookups done be secure implementations need to be implemented in a constant-time manner.
The toy example shows how to use LLVM’s Memory Sanitizer to detect whether table lookup is constant-time. Program starts with initializing table pow2 with powers of two in a range \(\left\langle 2^0, 2^{64} \right\rangle\). Then it reads \(x\) from the command line to the variable secret, uses it to get \(2^x\) from the table and returns the result.
In the first step, we want to ensure that MSan triggers UUM whenever program execution depends on the value of secret variable, if it does - UUM must be triggered. Fortunately, the LLVM’s MemorySanitizer API offers such a possibility, the __msan_allocated_memory marks address ranges as containing undefined or defined data, exactly what we need. All the MemorySanitizer API functions are located in the msan_interface.h header, which needs to be included in the code. Let’s look at the example below:
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <sanitizer/msan_interface.h>
#define POW2_NUM 64
static uint64_t pow2[POW2_NUM];
static inline uint64_t select_n(uint64_t n) {
return pow2[n];
}
int main(int argc, const char* argv[]) {
uint64_t ret, secret;
// Initialize a table with powers of 2
for (size_t i=0; i<64; i++) {
pow2[i] = 1ULL << i;
}
secret = atoi(argv[1]);
// Denote "secret" variable as uninitialized
__msan_allocated_memory(&secret,sizeof(secret));
// Time dependent operation possible load from cache or memory
ret = select_n(secret);
// Denote memory as defined to eliminate false possitive, due
// to non constant-time implementation of printf
__msan_unpoison(&secret, sizeof(secret));
// Denote also 'ret' in case shadow bits were propagated
__msan_unpoison(&ret, sizeof(ret));
printf("2^%lu = %lu\n", secret, ret);
}In that code, the select_n function performs memory lookup in a table pow2. Just before the function is called, 64-bits (8 bytes) of memory storing secret is denoted as uninitialized. That’s done by __msan_allocated_memory function. Then program calls the select_n function and at this point, UUM should be triggered. To avoid reporting a false positive error (caused by printf), the secret and ret are marked as defined, just after select_n returns. The result of the run is as expected:
> clang -g -fsanitize=memory -fsanitize-memory-track-origins=2 -fno-omit-frame-pointer test.c
> ./a.out 47
==1307703==WARNING: MemorySanitizer: use-of-uninitialized-value
#0 0x55f795fe2a1c in select_n /home/kris/test.c:11:12
#1 0x55f795fe269f in main /home/kris/test.c:26:11
#2 0x7fc798ac8b24 in __libc_start_main (/usr/lib/libc.so.6+0x27b24)
#3 0x55f795f6114d in _start (/home/kris/a.out+0x2014d)
Uninitialized value was stored to memory at
#0 0x55f795fe299e in select_n /home/kris/test.c:10
#1 0x55f795fe269f in main /home/kris/test.c:26:11
#2 0x7fc798ac8b24 in __libc_start_main (/usr/lib/libc.so.6+0x27b24)
Memory was marked as uninitialized
#0 0x55f795fbd1bb in __msan_allocated_memory (/home/kris/a.out+0x7c1bb)
#1 0x55f795fe2647 in main /home/kris/test.c:24:5
#2 0x7fc798ac8b24 in __libc_start_main (/usr/lib/libc.so.6+0x27b24)
SUMMARY: MemorySanitizer: use-of-uninitialized-value /home/kris/test.c:11:12 in select_n
ExitingExecution correctly triggers UUM at line 11, which is precisely where table lookup is done. Sanitizer also reports some information about origin of the problem. Generation of that information is enabled by -fsanitize-memory-track-origins=2 flag and proves to be quite useful during designing functions with constant-time execution.
Detection works that’s excellent. Let’s try to use it now on a code that’s constant time and see if UUM is not triggered. Following implementation is functionally equivalent to select_n, but now table lookup is done in constant time. Namely, it always goes thru all the elements of the table. The function calculates a mask variable, which sets all the bits only when element n is processed. Then thanks to logical & value is copied to the variable ret.
static inline uint64_t const_select_n(uint64_t n) {
uint64_t mask, sign, i, ret = 0;
sign = 1ULL << (63 - n);
// Always iterate over all elements
for (i=0; i<POW2_NUM; i++, sign<<=1) {
// Arithmetical shift right propagates MSB if
// set. Thanks to 'sign' set above, this is
// done only once during whole iteration.
mask = ((int64_t)sign) >> 63;
// With correctly set mask only one value
// is assigned to 'a' variable
ret |= pow2[i] & mask;
}
return ret;
}We can now swap the call to select_n with a call to const_select_n. Such implementation doesn’t trigger UUM anymore, as execution doesn’t depend on uninitialized data - the program always reads the whole table. On the flip side, the implementation of const_select_n is much more complicated to analyse, so tools are needed.
> clang -g -fsanitize=memory -fsanitize-memory-track-origins=2 -fno-omit-frame-pointer test.c
> ./a.out 47
2^47 = 140737488355328
>Utility called ct_check.h
Both, the Memcheck and Memory Sanitizer provide programmatic API, that can be used to design constant-time code. The ct_check provides a unified API for using both of those tools. A flag is used at compile time to control which tool to use. At the development stage, I use both tools- MSan is faster and gives more information in the final report, checks by Memcheck are more granular. Such a wrapper allows writing code only once and hence it is quite useful.
The ct_check.h exposes following functions:
| API | Description |
|---|---|
ct_poison |
Marks bytes as uninitialized. Switches on constat time checks for certain memory regions. It is wrapper around __msan_allocated_memory and VALGRIND_MAKE_MEM_UNDEFINED |
ct_purify |
Marks bytes as initialized. Switches off constat time checks (operation opposite to ct_poison) |
ct_print_shadow |
Prints state of shadow bits for uninitialized memory region. |
ct_expect_uum |
Instructs the compiler that it expects UUM after a call to this function. It works only with LLVM, useful for testing. |
ct_require_uum |
Ensures that UUM was before reaching this function. It works only with LLVM, useful for testing. Usually used in blocks ct_expect_uum(); do_non_ct_stuff(); ct_require_uum(); |
With that set of functions, I’ve used tests implemented by A. Lagnley to ensure the correctness of MSan and ctgrind are the same. Implementation of those tests with ct_check.h is here, but indeed, results are the same.
Applying ct_check.h to the existing implementation
Instead of toy-code, let’s now take an existing, modern cryptographic implementation, which was vulnerable to timing attacks and see if Memory Sanitizer can detect a problem in vulnerable code. Quantum-safe cryptographic implementations are currently my main focus, so I’ll apply it to one of Key Encapsulation Mechanism (KEM) submitted to NIST for post-quantum standardization. All the code presented below comes from PQC library available on Github (branch called blog/frodo_constant_time_issue).
A KEM is defined by 3 algorithms. A key generation returning pair of public and private keys, encapsulation algorithm which uses the public key to return shared secret in plain form and in encrypted form as ciphertext. Finally, decapsulation algorithm, that takes ciphertext and secret key as an input and returns shared secret, which then can be used for symmetric encryption (i.e. in TLS). To avoid leaking the secret key, the decapsulation function must ensure that the operation done on the private key is constant-time. This problem has been reported in FrodoKEM and exploited in recent paper. In that work, the authors propose (section 3) a generic side-channel technique that can be applied to recover the secret key of (LWE-based) KEM. Then (in section 4) describes how to use that technique to recover the FrodoKEM key. I highly recommend the paper (or video) to anybody interested in secure cryptographic implementations.
The following, variable time, implementation allowed attack to succeed.
// https://github.com/kriskwiatkowski/pqc/blob/e57a8915834e08998f1a93f3d111cfaf3fcd94a7/src/kem/frodo/frodokem640shake/clean/kem.c#L229
int PQCLEAN_FRODOKEM640SHAKE_CLEAN_crypto_kem_dec(uint8_t *ss, const uint8_t *ct, const uint8_t *sk) {
...
if (memcmp(Bp, BBp, 2*PARAMS_N*PARAMS_NBAR) == 0 &&
memcmp(C, CC, 2*PARAMS_NBAR*PARAMS_NBAR) == 0) {
// Load k' to do ss = F(ct || k')
memcpy(Fin_k, kprime, CRYPTO_BYTES);
} else {
// Load s to do ss = F(ct || s)
// This branch is executed when a malicious ciphertext is decapsulated
// and is necessary for security. Note that the known answer tests
// will not exercise this line of code but it should not be removed.
memcpy(Fin_k, sk_s, CRYPTO_BYTES);
}The ciphertext is a concatenation of two parts ciphertext = Bp || C. The decapsulation function, implemented by FrodoKEM, uses a secret key to decrypt the ciphertext, encrypt it again and compares a result with ciphertext received (see Fujisaki-Okamoto transform). That is what is being done in the code above. Values, BBp and CC represent ciphertext that was recomputed during decapsulation. Those values are compared with received ciphertext. If the comparison succeeds, the shared secret sk_kis returned, otherwise the function returns some random value.
There are two problems related to variable time execution:
- comparison uses
memcmp: this function is not constant-time - it fails as soon as it detects the first difference - it is used in short-circuit evaluation: in case first
memcmpreturns a value different than0, secondmemcmpis not called. Hence that’s also not constant-time behaviour.
The first issue is already enough to recover the private key. Let’s see if Memory Sanitizer will help to design constant-time implementation. I’m using PQC library, which integrates both variable and constant time decapsulation in FrodoKEM/640. Let’s start with a unit test:
// Uses GTEST and C++
TEST(Frodo, CtDecaps) {
// Get descriptor of an algorithm
const pqc_ctx_t *p = pqc_kem_alg_by_id(PQC_ALG_KEM_FRODOKEM640SHAKE);
// Initialize buffers for KEM output
std::vector<uint8_t> sk(pqc_private_key_bsz(p));
std::vector<uint8_t> pk(pqc_public_key_bsz(p));
std::vector<uint8_t> ct(pqc_ciphertext_bsz(p));
std::vector<uint8_t> ss(pqc_shared_secret_bsz(p));
bool res;
// Generate key pair and perform encapsulation
ASSERT_TRUE(pqc_keygen(p, pk.data(), sk.data()));
ASSERT_TRUE(pqc_kem_encapsulate(p, ct.data(), ss.data(), pk.data()));
// Mark secret material as uninitialized, so that variable time implementation causes UUM.
// First 16 bytes is a shared secret, then next 9616 is just a public key, and then next
// 10240 is another part of secret material (a secret matrix S used by FrodoKEM). Both
// shared secret and matrix S not leak, but it is OK to do variable-time operations on
// public key.
ct_poison(sk.data(), 16);
ct_poison((unsigned char*)sk.data()+16+9616, 2*640*8);
// Decapsulate
res = pqc_kem_decapsulate(p, ss.data(), ct.data(), sk.data());
// Purify res to allow non-ct check by ASSERT_TRUE
ct_purify(&res, 1);
ASSERT_TRUE(res);
}The test is compiled with flags enabling Memory Sanitizer and origin tracking. When run, it correctly triggers UUM as expected.
./ut --gtest_filter="Frodo.CtDecaps"
Running main() from /home/kris/repos/pqc/3rd/gtest/googletest/src/gtest_main.cc
Note: Google Test filter = Frodo.CtDecaps
[==========] Running 1 test from 1 test suite.
[----------] Global test environment set-up.
[----------] 1 test from Frodo
[ RUN ] Frodo.CtDecaps
Uninitialized bytes in MemcmpInterceptorCommon at offset 0 inside [0x7ffc94382040, 10240)
==3099896==WARNING: MemorySanitizer: use-of-uninitialized-value
#0 0x559140afe8cd in memcmp (build.msan.debug/ut+0xd08cd)
#1 0x5591410d5020 in PQCLEAN_FRODOKEM640SHAKE_CLEAN_crypto_kem_dec kem.c:233:9
#2 0x559140e75c5b in pqc_kem_decapsulate pqapi.c:112:13
#3 0x559140b30983 in Frodo_CtDecaps_Test::TestBody() test/ut.cpp:148:11
#4 0x559140de55a4 in void testing::internal::HandleSehExceptionsInMethodIfSupported<testing::Test, void>(testing::Test*, void (testing::Test::*)(), char const*) (build.msan.debug/ut+0x3b75a4)
...
Uninitialized value was stored to memory at
#0 0x5591410dec98 in PQCLEAN_FRODOKEM640SHAKE_CLEAN_key_decode /home/kris/repos/pqc/src/kem/frodo/frodokem640shake/clean/util.c:123:18
#1 0x5591410d44e0 in PQCLEAN_FRODOKEM640SHAKE_CLEAN_crypto_kem_dec /home/kris/repos/pqc/src/kem/frodo/frodokem640shake/clean/kem.c:184:5
...Runs as expected. In this case, Memory Sanitizer proves itself to be useful for the detection of code that’s not constant-time. It would find a bug in FrodoKEM if it was used.
In this case, ct_check.h has detected that uninitialized memory is used at line 229 (call to memcmp). It also gives a lot of additional output, due to origin tracking enabled (I have removed most of it). Now, to make the code constant-time, we must swap usage of memcmp with the implementation that compares bytes in constant-time. Implementation of such function looks like this:
// Compares in constant time two byte arrays of size 'n'
uint8_t ct_memcmp(const void *a, const void *b, size_t n) {
const uint8_t *pa = (uint8_t *) a, *pb = (uint8_t *) b;
uint8_t r = 0;
// XOR bytes in 'a' with corresponding bytes in 'b'. If
// all bytes are equal, 'r' will be == 0.
while (n--) { r |= *pa++ ^ *pb++; }
// Set most significant bit to 1 only if r!=0, otherwise
// r stays == 0
r = (r >> 1) - r;
r >>= 7;
// return last byte - 0 means a==b
return r;
}After swapping memcmp with ct_memcmp and running with Memory Sanitizer, UUM has not triggered anymore. And in this case, that’s BAD. The first problem is fixed, but the second problem is not - code is still not constant-time. We can verify that by running the same code in Valgrind (thanks to ct_check.h).
> valgrind --tool=memcheck ./ut --gtest_filter="Frodo.CtDecaps"
==3096880== Memcheck, a memory error detector
==3096880== Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al.
==3096880== Using Valgrind-3.17.0 and LibVEX; rerun with -h for copyright info
==3096880== Command: ./ut --gtest_filter=*CtDecaps*
==3096880==
Running main() from /home/kris/repos/pqc/3rd/gtest/googletest/src/gtest_main.cc
Note: Google Test filter = *CtDecaps*
[==========] Running 1 test from 1 test suite.
[----------] Global test environment set-up.
[----------] 1 test from Frodo
[ RUN ] Frodo.CtDecaps
==3096880== Conditional jump or move depends on uninitialised value(s)
==3096880== at 0x1B721E: PQCLEAN_FRODOKEM640SHAKE_CLEAN_crypto_kem_dec (kem.c:244)
==3096880== by 0x179C7D: pqc_kem_decapsulate (pqapi.c:112)
==3096880== by 0x11A4AD: Frodo_CtDecaps_Test::TestBody() (ut.cpp:148)
...Ok, Memcheck correctly reports an error. Interesting, but why?
Shadow memory propagation: MSan vs Valgrind
It took me some time to understand why it doesn’t work. It turns out that rules for shadow memory propagation are different in Memcheck and LLVM’s Memory Sanitizer. After analysing FrodoKEM, I’ve found out that the root cause boils down to the following example:
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include "common/ct_check.h"
int main(int argc, const char* argv[]) {
// Store 1 bit of first argument provided at command line
uint16_t sign = ((uint16_t)atoi(argv[1])) & 1;
uint16_t s;
// Use ct_poison and logical AND to mark least significant bit
// of 2-byte value as uninitialized.
ct_poison(&sign, 2);
sign = sign & 1;
// Print shadow memory - should produce output 01 00.
// It means that only least significant bit is uninitialized,
// the rest is properly initialized.
printf("Shadow memory: \n");
ct_print_shadow(&sign, 2);
// On Intel, negation is two's complement operation. So depending
// on value of 'sign' (0 or 1), shadow propagation may be needed.
s = (-sign); // Same as 's = ~sign + 1'
ct_print_shadow(&s, 2);
// Take a branch depending on uninitialized value. Should trigger UUM.
s >>= 15;
ct_print_shadow(&s, 2);
if (s==0) {
printf("Branch A taken\n");
} else {
printf("Branch B taken\n");
}
}The program reads input from the command line and stores it in 16-bit value sign. It marks the least significant bit of sign as uninitialized and then negates the value of sign. Negation on Intel platform is done by Two’s complement operation, hence it is equal to s = ~sign + 1. So, if sign == 0, then ~sign == 0xFFFF and adding value 1 will cause all the bits to flip, hence uninitialized state should be propagated to all the bits (similar operation is done by frodo_sample_n function in FrodoKEM).
Finally, a branch is taken depending on the value of a most significant bit of s. An important point to notice here is that - execution path of the program depends on uninitialized data, so UUM should be triggered. Let’s run, first Memory Sanitizer.
> clang -g -O0 -DPQC_USE_CTSANITIZER -fsanitize=memory -fno-omit-frame-pointer -fno-optimize-sibling-calls test.c
> ./a.out 0
Shadow memory:
01 00
01 00
00 00
Branch A taken
> ./a.out 1
Branch B takenUUM happy, nothing reported. The ct_print_shadow shows the state of shadow memory - the second line shows that only the least significant bit is marked uninitialized, so after the right (logical) shift, all bits must be properly initialized. Now Memcheck:
> clang -g -O0 -DPQC_USE_CTGRIND -fno-omit-frame-pointer -fno-optimize-sibling-calls test.c
> valgrind --tool=memcheck ./a.out 0
==3156952== Memcheck, a memory error detector
==3156952== Command: ./a.out 0
Shadow memory:
01 00
FF FF
01 00
==3156952== Conditional jump or move depends on uninitialised value(s)
==3156952== at 0x109239: main (test.c:26)
Branch A takenAs expected UUM is not happy. It is clear that shadow propagation rules are different - memcheck propagates shadow memory following complement’s two operation and Memory Sanitizer uses some less strict rules.
Initially, I thought that’s a bug (reported in GH#1430, GH#1424, GH#1427), but MSan maintainers from Google made me realize (thanks!) that it is a design decision which allows to faster execution. Indeed, looking at shadow propagation rules, described in “MemorySanitizer: fast detector of uninitialized memory use in C++” (see chapter 3.3.1), it seems shadow memory propagation following carry propagation is not implemented for efficiency reasons.
Speed
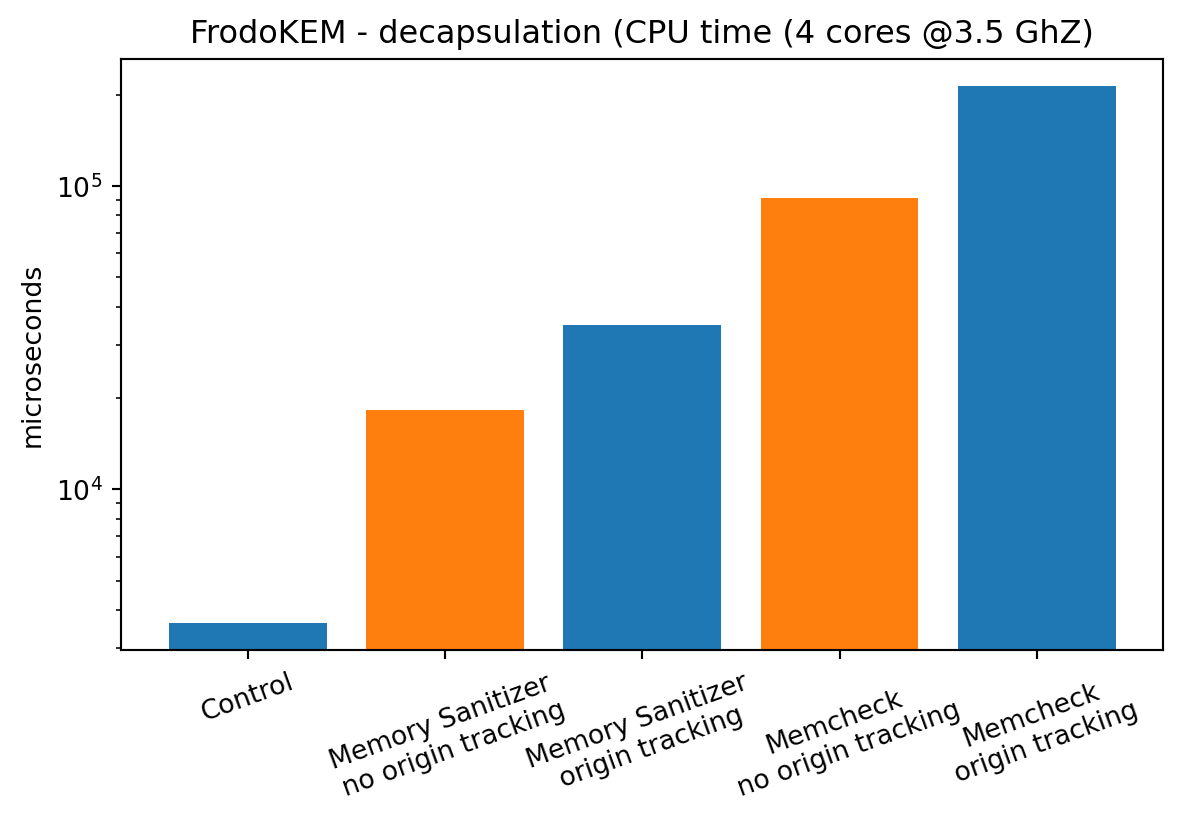
The graph below shows execution time difference when running FrodoKEM decapsulation without any instrumentation, with compile-time instrumentation Memory Sanitizer and then runtime instrumentation done by Valgrind’s Memcheck. The origin tracking is pretty expensive, so separated results are shown for a run with those enabled and disabled.
The control run shows that decapsulation takes around 3000 ms. With origin tracking disabled, the Memory Sanitizer seems to be 5 times slower comparing to the control run. Memcheck is 25 times slower. Then, with origin tracking enabled, Memory Sanitizer incurs 9x slowdown, in the case of Valgrind it is 59x - that’s a big difference.
Execution of a code instrumented at compile time is much faster. As described in the earlier section, Memcheck does more granular checks, so slower execution is expected. Nevertheless, the difference is significant. It should be noted that results do not include setup time. It means they are slightly biased as the whole runtime instrumentation done by Valgrind is not included in those results.
Conclusion, limitations and future direction
Memory Sanitizer, in some rare cases, is not going to discover uses of uninitialized data. This negatively impacts checking constant-time implementations. But still, it is pretty good at a job. My CI runs a build with Memory Sanitizer anyway, so adding extra checks has zero costs. Nevertheless, at the development stage, I use both, Memcheck and MSan the additional assurance provided by Memcheck is needed. I think it would be useful to have a possibility of controlling rules for shadow memory propagation in Memory Sanitizer. I.e. a compilation flag to use for choosing between more performant or more granular checks.
But what I would like to see in the future is a type system and better integration with a build system. Imagine that all the variables in the code that are used to store sensitive data, could use some kind of “secure” type (or annotation). Then, by introducing special build configuration, we could tell build system to instrument the code in a way that data using “secure” type is automatically marked uninitialized. In case of non constant-time access and with proper unit-tests, UUM detector would automatically report errors. I think it is an interesting feature for modern programming language like Rust, which seems to occupy a space of secure implementations.
Comming back to current state of art, it is also worth to mention that Memory Sanitizer has some additional limitations: * it is supported by Linux/x86_64, NetBSD and FreeBSD only * requires to instrument all memory accesses in the program. This includes standard C++ library (i.e. used by gtest). Instructions here describe how to instrument and integrate libc++ into a project.
Finally, side-channel attacks are much more complicated and there is no single tool which will be able to detect them. But from the other hand problems like the one in FrodoKEM, described above, are pretty basic. Automatic detection of such bugs is possible and and should be done by tools, so that Cryptography Engineers can spent time on more interesting things.